[Java] HikariCP DB ConnectionTimeout에 대한 Troubleshooting
20 Dec 2022HikariCP DB ConnectionTimeout에 대한 Troubleshooting
업무를 보던중 사내 API서버가 죽는 일이 벌어졌습니다. 다수의 서버가 존재하지만 하나의 서버만 CPU가 급격히 증가하더니 뻗어버렸습니다.
갑자기 무수한 요청이 오더니 죽어버린 서버..
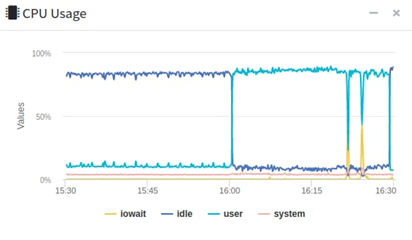
무슨일인고.. 하고 서버로그를 보니, HikariCP가 Connecion을 얻을 수 없어서 timeoutException을 발생시켰다는 로그를 발견했습니다.
java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30010ms.
at com.zaxxer.hikari.pool.HikariPool.createTimeoutException(HikariPool.java:696) ~[HikariCP-4.0.3.jar:na]
at com.zaxxer.hikari.pool.HikariPool.getConnection(HikariPool.java:197) ~[HikariCP-4.0.3.jar:na]
at com.zaxxer.hikari.pool.HikariPool.getConnection(HikariPool.java:162) ~[HikariCP-4.0.3.jar:na]
at com.zaxxer.hikari.HikariDataSource.getConnection(HikariDataSource.java:128) ~[HikariCP-4.0.3.jar:na]
at org.hibernate.engine.jdbc.connections.internal.DatasourceConnectionProviderImpl.getConnection(DatasourceConnectionProviderImpl.java:122) ~[hibernate-core-5.6.7.Final.jar:5.6.7.Final]
at org.hibernate.internal.NonContextualJdbcConnectionAccess.obtainConnection(NonContextualJdbcConnectionAccess.java:38) ~[hibernate-core-5.6.7.Final.jar:5.6.7.Final]
at org.hibernate.resource.jdbc.internal.LogicalConnectionManagedImpl.acquireConnectionIfNeeded(LogicalConnectionManagedImpl.java:108) ~[hibernate-core-5.6.7.Final.jar:5.6.7.Final]
at org.hibernate.resource.jdbc.internal.LogicalConnectionManagedImpl.getPhysicalConnection(LogicalConnectionManagedImpl.java:138) ~[hibernate-core-5.6.7.Final.jar:5.6.7.Final]
at org.hibernate.internal.SessionImpl.connection(SessionImpl.java:516) ~[hibernate-core-5.6.7.Final.jar:5.6.7.Final]
at org.springframework.orm.jpa.vendor.HibernateJpaDialect.beginTransaction(HibernateJpaDialect.java:152) ~[spring-orm-5.3.17.jar:5.3.17]
at org.springframework.orm.jpa.JpaTransactionManager.doBegin(JpaTransactionManager.java:421) ~[spring-orm-5.3.17.jar:5.3.17]
...
첫번째 HikariCP 튜닝
처음 이슈트래킹시 한서버에 급격한 요청으로 인해, API 서버의 Connection Pool에서 Connection이 부족해 일어나는 현상으로 파악했습니다.
그러나 다시 생각해보면 위에 생각은 틀린 생각이었습니다.
수많은 요청이 들어와 Connection이 부족하게 된다면 다른 서버에도 영향이 갔을것인데 하나의 서버에만 문제가 생겼다는 점과 그렇다고 또 요청의 수가 서버가 죽을정도로 많지는 않았다는 점
그외 몇가지로 인해 찜찜함을 가지고, HikariCP의 설정을 확인 해봤습니다.
먼저 한가지 원인중 하나로 봤던것 중 하나는 사내에서 사용하는 MySql의 wait_timeout의 시간과 HiakriCP에서 사용하는 maxLifetime에서 차이에서 있었습니다.
사내 MySql의 표준 wait_timeout의 설정은 25초로 HikariCP 설정의 maxLifetime 최소값보다 적었기 때문에 항상 HikariCP가 Connection을 반환하기도 전에 MySql에서 반납하는 현상이 벌어졌었습니다.
2022-XX-XX XX:XX:XX.XXX WARN 12212 --- [n(4)-10.20.2.28] com.zaxxer.hikari.pool.PoolBase : HikariPool-1 - Failed to validate connection com.mysql.jdbc.JDBC4ReplicationMySQLConnection@1486b850
(Communications link failure The last packet successfully received from the server was 23,137 milliseconds ago. The last packet sent successfully to the server was 0 milliseconds ago.).
Possibly consider using a shorter maxLifetime value.
(결론은 아니었습니다 ㅎㅎ)
설정을 확인해보니, 기존의 Connection 설정이 요청의 수에 조금 부족한 감이 있었고 HikariCP의 설정을 변경한 뒤 경과를 지켜보도록 하였습니다.
spring:
datasource:
driver-class-name:
url:
username:
password:
hikari:
maximum-pool-size: 20
max-lifetime: 30000
connection-timeout: 10000
validation-timeout: 10000
하지만 일주일뒤 서버는 동일한 증상을 발생시키며 또 뻗어버렸습니다.
두번째 슬로우 쿼리 분석 및 HikariCP 로그 추가
서버가 뻗은 시점에 들어온 요청들을 분석하고 슬로우 쿼리가 발생하는 API에 대해 분석하였습니다.
하지만 쉽지 않았던 이유는 전체적으로 API의 요청에서 응답의 시간과, JOIN도 없는 간단한 쿼리 마저도 3~4초정도 소요가 되었기 때문에 근본적인 슬로우 쿼리를 찾기가 어려웠습니다. DF팀에서 연락이와 과부하 직전에 돌아간 슬로우 쿼리들에 대한 목록을 받았고, 쿼리에 대한 튜닝을 진행하기로 하였습니다.
이어서, DB의 Connection의 누수의 위치를 찾기위해 Hikari 로그를 출력해 파악하기로 하였습니다.
해당 설정은 아래와 같이 설정하면 확인 할 수 있습니다.
logging:
level:
com.zaxxer.hikari.HikariConfig: DEBUG
com.zaxxer.hikari: TRACE
logging에 Hikari에 대한 옵션을 추가할 경우 아래와 같이 HikariCP에서 관리하고 있는 Connection Pool에 대한 로그가 출력됩니다.
2022-12-22 01:18:07.315 DEBUG 22340 --- [onnection adder] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection conn5: url=jdbc:h2:mem:testdb user=SA
2022-12-22 01:18:08.080 DEBUG 22340 --- [nnection closer] com.zaxxer.hikari.pool.PoolBase : HikariPool-1 - Closing connection conn2: url=jdbc:h2:mem:testdb user=SA: (connection has passed maxLifetime)
2022-12-22 01:18:08.156 DEBUG 22340 --- [l-1 housekeeper] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Pool stats (total=5, active=0, idle=5, waiting=0
위의 설정을 추가한다면, 위에서 볼 수 있듯이 Connection이 추가되거나 닫히는것을 확인 할 수 있습니다. 만약 Added가 발생한 뒤 Closing이 발생하지 않는다면, 해당 커넥션은 실종(?)된거나 다름이 없는 거였습니다.
또한 Pool stats 로그에서 Connection의 상태(total : 전체, active : 사용중, idel : 유후, wating : 대기중인 요청) 또한 확인이 가능합니다.
하지만 운영서버의 로그는 어마어마하게 올라오기 때문에 모든 커넥션을 확인하기가 어려웠습니다.
그래서 또하나의 설정을 추가했습니다.
spring:
datasource:
hikari:
leakDetectionThreshold: 4000
leakDetectionThreshold 설정은 Connection이 leak(누수)가 되는 것을 감지하는 옵션으로 완벽하게 누수현상이라고 할 수는 없지만, 누수로 의심되는 위치를 알려주는 옵션입니다.
예를 들면 아래와 같이 로그가 나타나게 됩니다. Connection의 누수가 의심되는 위치를 알려주는 옵션입니다.
2022-12-22 01:52:53.888 WARN 18620 --- [l-1 housekeeper] com.zaxxer.hikari.pool.ProxyLeakTask : Connection leak detection triggered for conn0: url=jdbc:h2:mem:testdb user=SA on thread http-nio-8080-exec-7, stack trace follows
java.lang.Exception: Apparent connection leak detected
at com.zaxxer.hikari.HikariDataSource.getConnection(HikariDataSource.java:128) ~[HikariCP-4.0.3.jar:na]
at org.hibernate.engine.jdbc.connections.internal.DatasourceConnectionProviderImpl.getConnection(DatasourceConnectionProviderImpl.java:122) ~[hibernate-core-5.6.7.Final.jar:5.6.7.Final]
...
at com.tax.refund.domain.user.service.UserService$$EnhancerBySpringCGLIB$$317f9a0.login(<generated>) ~[main/:na]
at com.tax.refund.domain.user.api.UserController.login(UserController.java:41) ~[main/:na]
...
만약 누수가 아니라면 다시한번 정정 로그를 내보내 줍니다.
2022-12-22 01:56:21.205 INFO 17092 --- [nio-8080-exec-3] com.zaxxer.hikari.pool.ProxyLeakTask : Previously reported leaked connection conn0: url=jdbc:h2:mem:testdb user=SA on thread http-nio-8080-exec-3 was returned to the pool (unleaked)
더 자세한 HikariCP의 Logging에 대한 내용은 아래의 내용을 참고 바랍니다.
이렇게 Connetion 누수에 대한 정보를 얻기위해 HikariCP의 로그 설정을 운영서버에 배포하고 동일한 현상이 발생하기를 기다렸습니다.
이어서 또 같은 현상으로 서버 과부하가 발생했습니다.
leakDetectionThreshold 설정은 4초로 잡았기 때문에, 4초 이상 걸린 요청들은 전부 leak 관련 경고 문구가 출력 되었고, 해당 문구에 나온 API들을 분석하였습니다.
그후 특정 API에서 GC관련 에러가 발생하는것을 발견 할 수 있었습니다.
GC Overheat limit exceeded
GC 관련 에러에 대한 로그는 아래와 같습니다.
[20XX-XX-XX XX:XX:XX.XXX] [ERROR] [GET /] - o.s.t.i.TransactionInterceptor completeTransactionAfterThrowing - Application exception overridden by rollback exception
java.lang.OutOfMemoryError: GC overhead limit exceeded
해당 에러 로그에 대해 검색해보니 프로세스의 모든 CPU 가용 시간중 GC를 수집하게 되어 일시중지 하게 되는 시간이 98% 이상을 사용하게 되고 실제 Application 작업 시간이 2%미만이 될 경우 발생한다고 합니다.

해당 에러를 찾아 확인해보니 이제야 원인을 잡게된 듯 합니다.
실제로 해당 OutOfMemoryError 난 API를 분석해 보니, 회사의 소스라 공개를 할 수 는 없지만 특정 조건의 경우 null이 들어가 약 400,000 건 정도의 데이터가 조회되고 있었고, 조회 해온 데이터를 가지고 반복문을 돌려 2차가공을 진행하는 로직이 있었습니다.
실제로 해당 시각에 DB와 통신한 데이터 통신량을 보니 150MB정도의 어마어마한 양의 데이터를 읽어 들어온 흔적이 있었습니다.
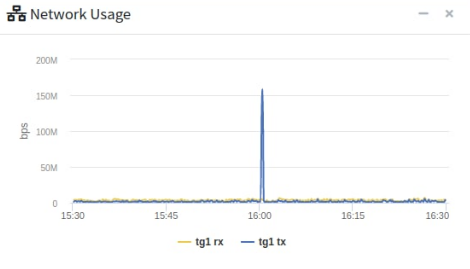
결국 근본적인 원인은 슬로우 쿼리가 원인 이었습니다. 해당 null이 들어가게 될 조건을 수정하여 이슈를 해결할 수 있었습니다.
정리
결국 HikariCP의 Connection 문제인줄 알았던 원인은 슬로우 쿼리가 문제였고, 시나리오를 정리하자면 아래와 같이 진행되었습니다.
- 과도한 슬로우 쿼리 및 데이터를 읽어 들어옴에 따라 CPU 사용량이 급격하게 증가
- 급격한 CPU 사용량에 따라 GC의 수집 시간이 어마어마하게 증가 곧 작업 일시중지 시간이 98% 이상을 넘어서
GC overhead limit exceeded발생 - 결국 GC의 수집으로 인한 일시중지 시간이 길어지다보니, Connection의 반환 및 부여하기 위한 작업진행의 어려움
- 모든 요청이 느려지고, 과부화 발생
SQLTransientConnectionException발생
처음으로 맞이하는 대규모 서비스에서의 에러였습니다. 이상하게 약속이 있는날만 골라서 서버가 터져 많은 애로사항이 있었으나, 좋은 경험 및 공부를 하게된 계기가 된 것 같습니다.